Introduction to guardianapi
Evan Odell
2022-01-31
Source:../docs/vignettes/introduction.Rmd
introduction.RmdFunctions
guardianapi contains functions to search and retrieve
articles, tags and editions from the Guardian
open data platform.
Let’s look at a few reviewers. For example, I noticed that comedy critic Brian Logan seemed to give out very few five star or one star reviews, so I wanted to see if that was true. I’ve included all his reviews from 2002–2018
library(guardianapi)
library(dplyr)
library(lubridate)
library(ggplot2)
logan_search <- gu_items(query = "profile/brianlogan")
logan_search$star_rating <- as.numeric(logan_search$star_rating)
logan_reviews <- logan_search %>%
filter(!is.na(star_rating),
web_publication_date >= as.Date("2002-01-01"),
web_publication_date <= as.Date("2018-12-31"))
logan_reviews$year <- as.factor(year(logan_reviews$web_publication_date))
logan_summary <- logan_reviews %>%
group_by(year, star_rating) %>%
summarise(count = n()) %>%
mutate(perc = count/sum(count)) %>%
ungroup() %>%
mutate(star_rating = factor(star_rating, levels = c(5,4,3,2,1)))
p_logan <- ggplot(data = logan_summary,
aes(x = year, y = count, group = star_rating)) +
geom_line(aes(colour = star_rating), size = 1, alpha = 0.9) +
scale_colour_viridis_d(name = "Rating") +
labs(x="Year", y="Number of Review with Rating") +
theme(axis.text.x = element_text(angle = 45, vjust=0.5))
p_logan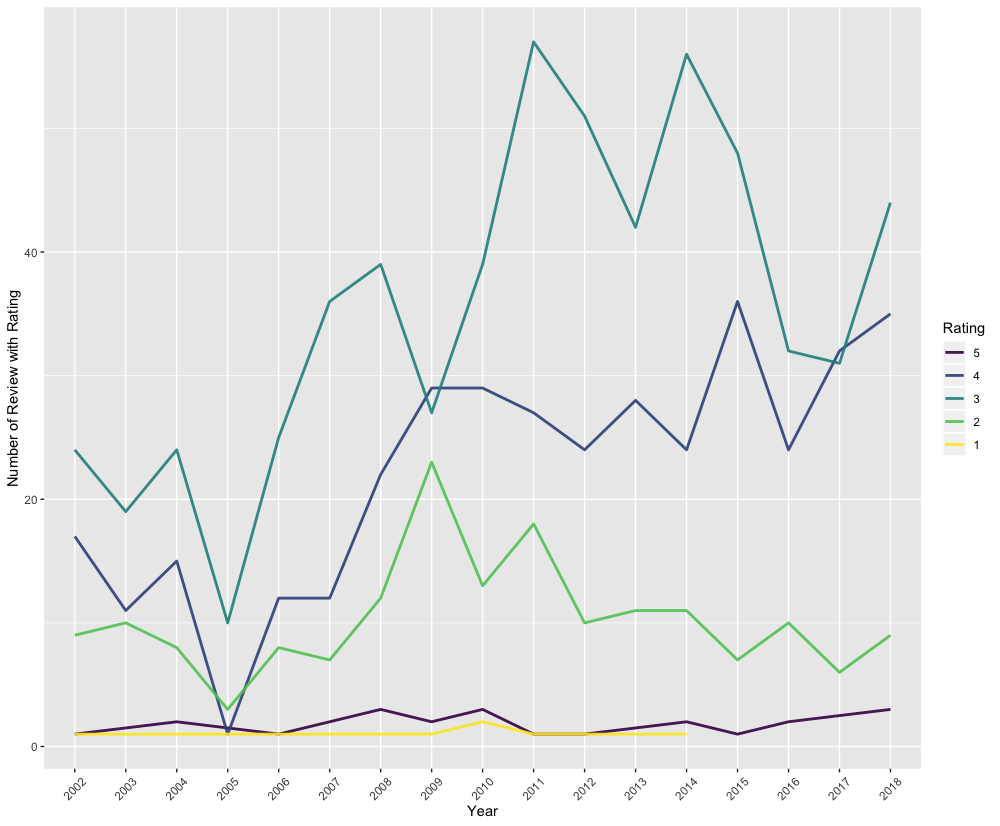
p_logan_area <- ggplot(data = logan_summary,
aes(x = year, y = perc, group = star_rating)) +
geom_area(aes(fill = star_rating)) +
scale_y_continuous(labels = scales::percent) +
scale_fill_viridis_d(name = "Rating") +
labs(x="Year", y="Number of Review with Rating") +
theme(axis.text.x = element_text(angle = 45, vjust=0.5))
p_logan_area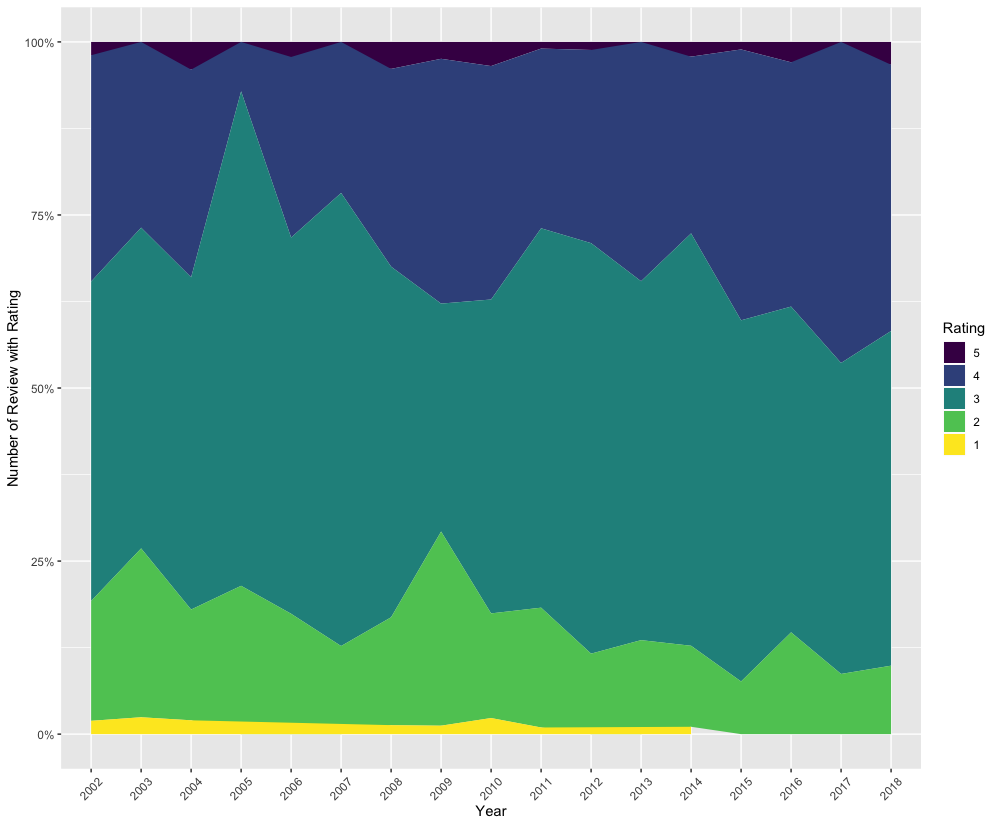
As you can see here, Brian Logan is pretty stingy with five star reviews, and didn’t give out a single five star rating in all of 2017. Likewise, he hasn’t completed panned any act with a single star since 2014.
Now let’s take a look at film critic Peter Bradshaw. I’ve used the same time span, and I’ve removed the single 0-star rating given to the 2008 film Boat Trip. There are more than four times as many film reviews from Peter Bradshaw as there are comedy reviews from Brian Logan over the same time period.
library(dplyr)
library(lubridate)
library(ggplot2)
bradshaw_search <- gu_items(query = "profile/peterbradshaw")
bradshaw_search$star_rating <- as.numeric(bradshaw_search$star_rating)
bradshaw_reviews <- bradshaw_search %>%
filter(!is.na(star_rating), star_rating != 0,
web_publication_date >= as.Date("2002-01-01"),
web_publication_date <= as.Date("2018-12-31"))
bradshaw_reviews$year <- as.factor(year(bradshaw_reviews$web_publication_date))
bradshaw_summary <- bradshaw_reviews %>%
group_by(year, star_rating) %>%
summarise(count = n()) %>%
mutate(perc = count/sum(count)) %>%
ungroup() %>%
mutate(star_rating = factor(star_rating, levels = c(5,4,3,2,1)))
p_bradshaw <- ggplot(data = bradshaw_summary,
aes(x = year, y = count, group = star_rating)) +
geom_line(aes(colour = star_rating), size = 1, alpha = 0.9) +
scale_colour_viridis_d(name = "Rating") +
labs(x="Year", y="Number of Review with Rating") +
theme(axis.text.x = element_text(angle = 45, vjust=0.5))
p_bradshaw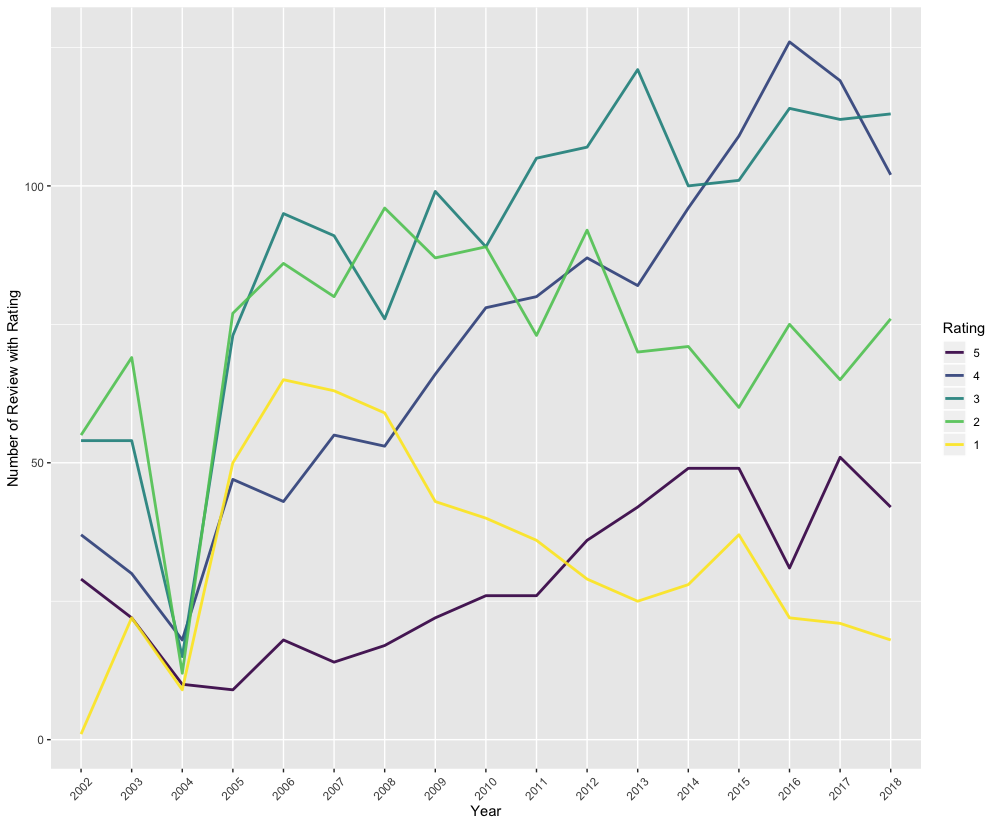
p_bradshaw_area <- ggplot(data = bradshaw_summary,
aes(x = year, y = perc, group = star_rating)) +
geom_area(aes(fill = star_rating)) +
scale_y_continuous(labels = scales::percent) +
scale_fill_viridis_d(name = "Rating") +
labs(x="Year", y="Number of Review with Rating") +
theme(axis.text.x = element_text(angle = 45, vjust=0.5))
p_bradshaw_area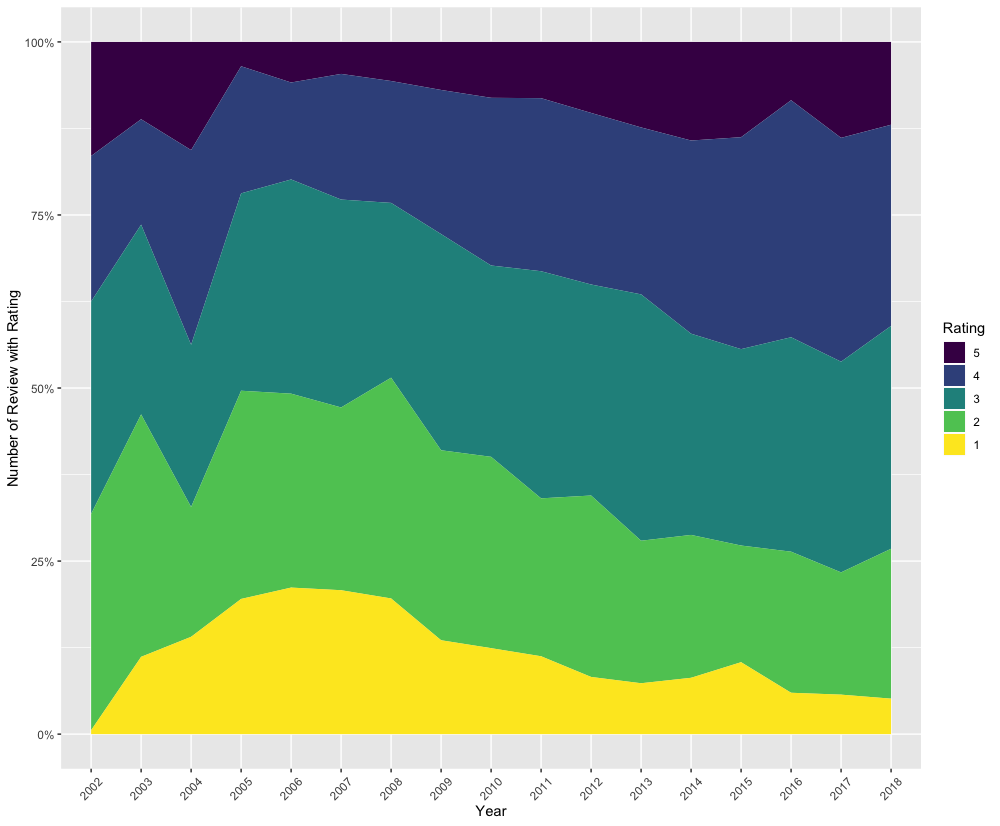
We can compare the distributions of ratings given by the two critics.
bradshaw_reviews$byline <- "Peter Bradshaw"
logan_reviews$byline <- "Brian Logan"
comp_df <- bind_rows(logan_reviews, bradshaw_reviews) %>%
mutate(star_rating = as.numeric(star_rating))
comp_df2 <- comp_df %>%
group_by(star_rating, byline) %>%
summarise(count = n()) %>% group_by(byline) %>%
mutate(perc = count/sum(count))
comp_p <- ggplot(comp_df,
aes(x = star_rating, y = ..density.., fill = byline)) +
geom_histogram(position="dodge", bins = 5, alpha = 0.5) +
scale_y_continuous(labels = scales::percent) +
scale_fill_viridis_d(end = 0.9, option = "inferno") +
labs(x = "Star Rating", y = "", fill = "") +
theme(legend.position = "bottom") +
geom_line(aes(x = star_rating, y = perc,
colour = byline, group = byline), data = comp_df2,
size = 1) +
scale_colour_viridis_d(end = 0.9, option = "inferno") +
guides(colour = FALSE)
comp_p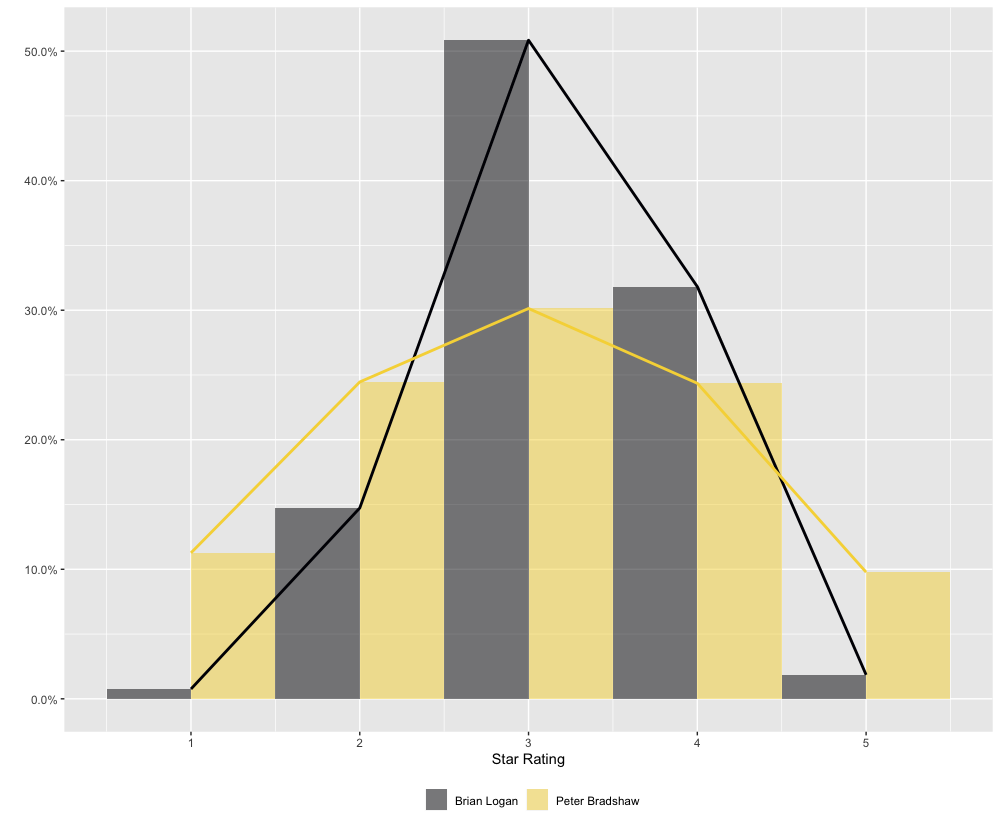
We can also use gu_content() for more general queries.
For example, here’s all the articles returned for “relationships”
between the two given dates:
relations <- gu_content(query = "relationships", from_date = "2018-11-30",
to_date = "2018-12-30")
tibble::glimpse(relations)#> # A tibble: 170 × 44
#> id type section_id section_name web_publication_da… web_title web_url
#> <chr> <chr> <chr> <chr> <dttm> <chr> <chr>
#> 1 music/… arti… music Music 2018-12-02 09:10:28 The 1975:… https:/…
#> 2 film/2… arti… film Film 2018-12-18 09:48:12 Woman cla… https:/…
#> 3 lifean… arti… lifeandst… Life and st… 2018-12-10 09:00:39 I’m in a … https:/…
#> 4 politi… arti… politics Politics 2018-12-25 18:00:00 'Special … https:/…
#> 5 footba… arti… football Football 2018-12-19 11:08:41 Kelly Cat… https:/…
#> 6 film/2… arti… film Film 2018-12-14 15:06:11 Sondra Lo… https:/…
#> 7 footba… arti… football Football 2018-12-05 02:16:40 Mancheste… https:/…
#> 8 commen… arti… commentis… Opinion 2018-12-24 11:41:14 How to ge… https:/…
#> 9 books/… arti… books Books 2018-12-15 15:00:13 Dolly Ald… https:/…
#> 10 footba… arti… football Football 2018-12-09 18:00:20 Phoenix s… https:/…
#> # … with 160 more rows, and 37 more variables: api_url <chr>, tags <list>,
#> # is_hosted <lgl>, pillar_id <chr>, pillar_name <chr>, headline <chr>,
#> # standfirst <chr>, trail_text <chr>, byline <chr>, main <chr>, body <chr>,
#> # newspaper_page_number <chr>, star_rating <chr>, wordcount <chr>,
#> # comment_close_date <dttm>, commentable <chr>,
#> # first_publication_date <dttm>, is_inappropriate_for_sponsorship <chr>,
#> # is_premoderated <chr>, last_modified <chr>, …Use the tag parameter to limit articles to particular
sections:
relations_sex <- gu_content(query = "relationships", from_date = "2018-11-30",
to_date = "2018-12-30", tag = "lifeandstyle/sex")
relations_sex#> Rows: 5
#> Columns: 40
#> $ id <chr> "lifeandstyle/2018/dec/10/im-in-a-rel…
#> $ type <chr> "article", "article", "article", "art…
#> $ section_id <chr> "lifeandstyle", "lifeandstyle", "life…
#> $ section_name <chr> "Life and style", "Life and style", "…
#> $ web_publication_date <dttm> 2018-12-10 09:00:39, 2018-12-21 11:0…
#> $ web_title <chr> "I’m in a relationship with another m…
#> $ web_url <chr> "https://www.theguardian.com/lifeands…
#> $ api_url <chr> "https://content.guardianapis.com/lif…
#> $ tags <list> [<data.frame[10 x 13]>], [<data.fram…
#> $ is_hosted <lgl> FALSE, FALSE, FALSE, FALSE, FALSE
#> $ pillar_id <chr> "pillar/lifestyle", "pillar/lifestyle…
#> $ pillar_name <chr> "Lifestyle", "Lifestyle", "Lifestyle"…
#> $ headline <chr> "I’m in a relationship with another m…
#> $ standfirst <chr> "We kiss and cuddle, but he won’t go …
#> $ trail_text <chr> "We kiss and cuddle, but he won’t go …
#> $ byline <chr> "Pamela Stephenson Connolly", "Anonym…
#> $ main <chr> "<figure class=\"element element-imag…
#> $ body <chr> "<p><strong>Until last year, I identi…
#> $ newspaper_page_number <chr> "7", "66", "83", NA, "44"
#> $ wordcount <chr> "387", "307", "2189", "759", "1559"
#> $ comment_close_date <dttm> 2018-12-13 09:00:39, 2018-12-23 21:00…
#> $ commentable <chr> "true", "true", "true", "false", "fal…
#> $ first_publication_date <dttm> 2018-12-10 09:00:39, 2018-12-21 11:00…
#> $ is_inappropriate_for_sponsorship <chr> "false", "false", "false", "false", …
#> $ is_premoderated <chr> "true", "true", "true", "false", "fal…
#> $ last_modified <chr> "2018-12-10T08:00:39Z", "2018-12-23T…
#> $ newspaper_edition_date <date> 2018-12-10, 2018-12-22, 2018-12-08, N…
#> $ production_office <chr> "UK", "UK", "UK", "UK", "UK"
#> $ publication <chr> "The Guardian", "The Guardian", "The …
#> $ short_url <chr> "https://gu.com/p/a5fad", "https://gu…
#> $ should_hide_adverts <chr> "false", "false", "false", "false", …
#> $ show_in_related_content <chr> "true", "true", "true", "true", "true"
#> $ thumbnail <chr> "https://media.guim.co.uk/35fd3d18854…
#> $ legally_sensitive <chr> "false", "false", "false", "false", "…
#> $ sensitive <chr> "true", NA, NA, NA, "true"
#> $ lang <chr> "en", "en", "en", "en", "en"
#> $ body_text <chr> "Until last year, I identified as a s…
#> $ char_count <chr> "2192", "1729", "12190", "4404", "866…
#> $ should_hide_reader_revenue <chr> "false", "false", "false", "false", "…
#> $ show_affiliate_links <chr> "false", "false", "false", "false", "…